Classification
Classification¶
Let’s begin our ML journey with the problem of classification.
As always, we begin with a practical usage for this problem. A very common usage of classification is employed with credit card companies, who want to predict if an applicant will default on their credit balances on not, based on some background checking. Let’s see this visually:
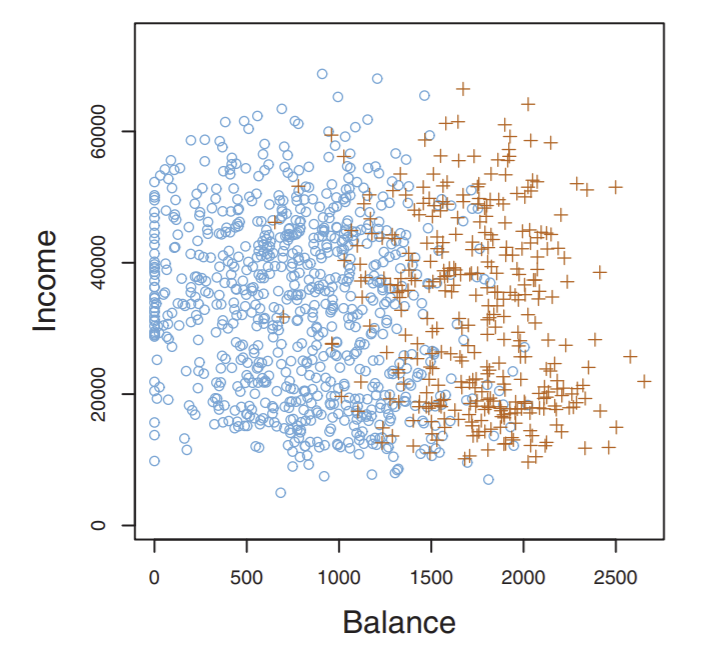
In the above graph, each point corresponds to a credit card user. Notice each person (each point) was defined by their credit balance and income - the two most important features that determine someone’s credit risk in this case. Points with a brown '+' are people who defaulted on their credit, and points with a blue 'o' are those who did not.
That’s great and all, but what can we do with this? Ideally, we want to use these examples (and the graph it makes) to classify whether a future applicant is a credit risk or not. Specifically, as stated in this book’s intro, we’re looking for some pattern in the data that can help with this classification.
First, to gain some intuition, let’s look at the distribution of the two features (balance and income) alone:
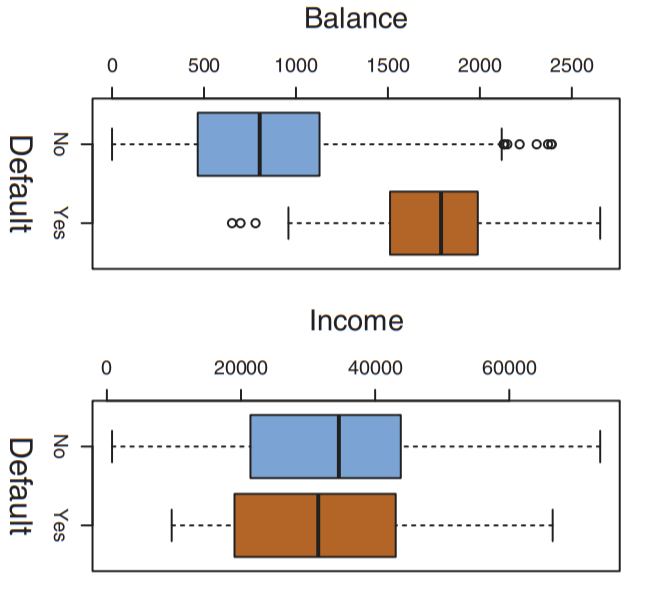
Note that the difference in balances for those who do default and those who don’t are significantly different, while income looks fairly similar. This means that balance is probably a more influential factor in classifying someone as a risk or not. However, that does not mean that income isn’t useful- not at all. We can still use it as sort of a “second-level” predictor: if we can’t tell if someone’s a risk based on their credit balance, then we use their income.
So a human can pretty easily use the data to predict whether a new applicant is a credit risk or not. For example, if you see someone with a 3000 dollar balance and 20K income, you’ll probably assign them as a pretty high credit risk. That’s fine. Anyone who you call to apply for a credit card will be pretty good at this.
But how can a machine learn how to do it? Well, humans have to basically “teach” the machine with a lengthy but (hopefully) not-too-complicated process. Let’s check it out.